作为一个 Java 程序员,Javadoc 大家都应该写过吧,是不是觉得写的时候特简单呢?相信看完本文后你会若有所思。另外,本文非常适合处女座程序员阅读。
句号
为什么是句号而不是其他的标点符号呢?因为这涉及到一个 JDK 文档生成的规则:
The first sentence of each doc comment should be a summary sentence, containing a concise but complete description of the API item. This means the first sentence of each member, class, interface or package description. (成员、类、接口或包注释的第一个句子将作为该注释项的总结,这个句子应该是言简意赅的)
既然提到了句子,那就说明应该用标准的方式——句号来进行第一个句子的断句识别。也许是为了简洁,Javadoc 工具并没有“多语言句号识别”这个特性,所以不管我们用什么语言撰写文档注释,断句符号都必须是英文状态下的句号——.
比如在 NetBeans IDE 里(默认编辑器配置)可以很直观的看到用于总结的第一个句子和后面描述的区别:

在生成 Javadoc 后,类概要页面我们可以看到最终的效果:

在使用中文撰写文档注释时,为了保持整体风格一致,在所有需要使用句号的地方有两种策略可选择:
- 都使用英文句号:这样做可以让生成的文档句号统一,但缺点是看上去有点别扭
- 只有第一个句子使用英文句号,其余地方都是要中文句号:这样做后生成的文档看上去比较顺眼,但别人可能会奇怪为什么第一个句号是 . 当然,最彻底的解决方案是不用中文写文档注释,这样就不存在要统一的问题了!
下面我们重点介绍各种你熟悉的或是不熟悉的 Javadoc 文档标记(它们很有内涵)
@author
该标记使用频率是所有文档标记中最高的,我想这是因为:
- 做好事要留名
- 使用超简单,就像在填表格(姓名: )一样自然
来看看大牛怎么写的:
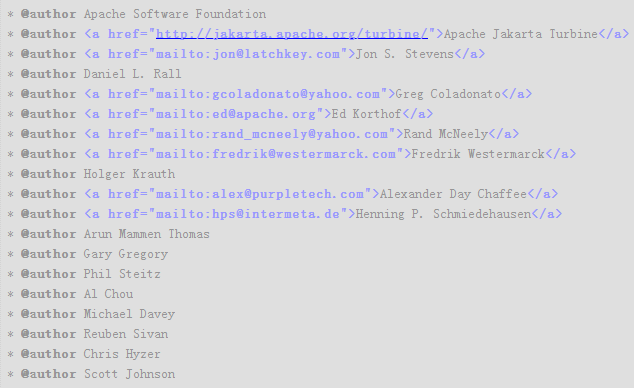
(from Commons Lang 2.5 StringUtils)
总结下来有三种写法:
- 纯文本
- 带邮箱链接
- 带 HTTP 链接
(个人建议用 HTTP 链接:打码时可以顺便推广一下自己的博客,哈哈)
另外,在 JDK 代码中我们经常看到 @author unascribed,意思是:“该代码第一原作者不是我,但我实在也不知道是谁,就记作无名氏吧”(这是多么严肃的一种版权意识啊)
@serialXXX
这个系列应该是最不常用的文档标记了,它们到底是干嘛用的呢?请看这里。
(我一次也没有使用过这些文档标记,看了官方文档后也还是没有搞懂怎么用,求各位指教)
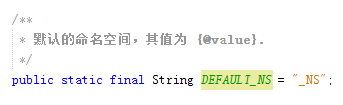
@value
这个文档标记非常实用(不光好用),可以用于生成被标记的常量字段的值。
直接用于常量字段时:
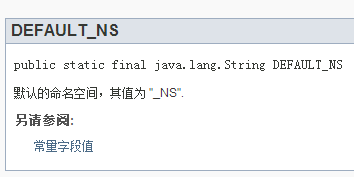
也可以使用引用方式:

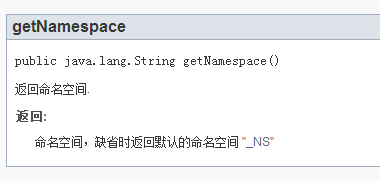
{@inheritDoc}
这个标签体现了 Java 面向对象的精辟所在:不但可以类可以集成,连文档都可以继承(足见 Java 在经典面向对象概念上的完备与圆润)。
比如有个计算面积的接口:

它的实现方法标注了 {@inheritDoc}(处女座阅读提示:无 .):

最后生成的文档:

- 基类的文档注释被继承到了子类
- 子类可以再加入自己的注释(特殊化扩展)
- @return @param @throws 也会被继承
其实在不写 {@inheritDoc} 的情况下也存在文档注释的继承,具体规则请看这里。
{@link} {@linkplain}
这两个链接标记大家用/见的应该比较多,但它们有什么区别、在什么场景下该怎么使用很少有人能够区分开(我猜你要用的时候一般也都是用 link 吧)。
看看官网的标准解释:

link 和 linkplain 的实参都是 package.class#member label 。唯一的不同就是因为字体不同,如果 label 是个纯文本,那就使用 linkplain 吧。(根据这点,我严重怀疑 Javadoc 文档标记的设计者是处女座,~ ~)
pre
没错,这就是那个 HTML 标签,用于显示“原始样子”的。这个标签在写 Javadoc 的时候非常有用,用或者不使用在打码的时候看上去差别不大:

但最终生成 apidocs 之后差别一目了然(处女座阅读提示:在源码文档注释中特别需要注意 pre 后 { 的位置,紧跟 ,无空格)*:
@since
这个从字面的意思上很好理解,所以使用的比较多(如同 @author、@version 一样)。但问题是大家写的时候表达的意思五花八门,常见的有:
想表达日期/时间 @since 2014-01-01 @since 2014-01-01 14:00:00
想表达可运行的 JDK 版本 @since JDK1.5
想表达加入这个元素的版本 @since 1.0.0
根据官方文档解释,@since 表达的是被标记元素是哪个发布版本引入的(3)。比如别人在我们的文档注释中看到

那他可以(应该)认为这个类是在该程序对外发布 1.0.0 版本时已经引入的。如果他要做二次开发,那他就可以很清晰的向后兼容了(我们在用 JDK 的时候就是这个场景)。
@version
提到了 @since 就自然会联想到 @version,因为它们的实参都是版本相关的。@version 要表达的是被标记元素自己的版本(注意对比 @since),也就是说这个版本只要代码改过就应该发生变化,而 @since 是不会变的。
官方文档也解释了怎么用好这个文档标记:通过 SCCS 字符 “%I%, %G%”,例如 1.39, 02/28/97(文件版本号, 日期)生成。但实际上很少有项目这么做(至少目前 Oracle JDK 没这么做,甚至都没有使用 @version,或者是使用了但最后由于特殊原因总体移除了),大家一般都是 @version 1.0.0 然后就再也不修改了,不管被标记的元素改了多少次(这样的做法还不如不写)。
当然,通过版本控制系统 hook 来做是比较经典的做法,不过这样总感觉没有把这个标记的能力完全发挥出来。在我们的项目里是这样使用的:@version 1.2.3.4, Jun 9, 2014
重点是版本号部分,在这个例子中从左到右(1.2.3.4)分别表示:
- 兼容性位 1,表示兼容性,如果 +1 了说明这个修改是不兼容的
- 特性位 2,表示已引入了两个特性,每次 +1 说明引入一个新特性
- 缺陷修复位 3,表示已经修复了 3 个缺陷,每次 +1 说明修复了一个缺陷
- 重构位 4,表示已经进行了 4 次重构,每次 +1 说明重构了一次
- 前面 3 位表达的意义和 Semantic Versioning 建议的一致,重构我觉得非常重要,所以也加了进来。
@exception @throws
这两兄弟的情况比 @link @linkplain 更纠结(人家 link 兄弟最起码可以区分出来使用场景)。按照官方文档解释:它们完全是同义词,没有任何区分。那当年 Sun 在 JDK1.2 的时候为什么要加入 @throws 呢——答案是起名失误了,词性没弄匹配:@throws Exception 比 @exception Exception 更符合语法,代入感更好!(细节:In javadoc, what is the difference between the tags @throws and @exception?)
标记总表
来张 Javadoc 文档标记总表:
| Tag | Introduced in JDK/SDK |
|---|---|
@author |
1.0 |
{@code} |
1.5 |
{@docRoot} |
1.3 |
@deprecated |
1.0 |
@exception |
1.0 |
{@inheritDoc} |
1.4 |
{@link} |
1.2 |
{@linkplain} |
1.4 |
{@literal} |
1.5 |
@param |
1.0 |
@return |
1.0 |
@see |
1.0 |
@serial |
1.2 |
@serialData |
1.2 |
@serialField |
1.2 |
@since |
1.1 |
@throws |
1.2 |
{@value} |
1.4 |
@version |
1.0 |
这个表是 JDK7 技术手册里的,从中我们可以看出,自 JDK1.5 以后就没有加过新的文档标记了,目测有两个原因:
Oracle:“这些已经足够开发人员使用了,没必要加新的了”
*Sun:“看吧,Oracle 严重缺乏折腾精神,当初不应该卖给它的” 文档标记介绍完了,下面我们来聊聊 Javadoc 相关的其他侃点。
getter/setter/isTrue
对于 POJO 来说,这几个方法的注释格式非常固定,一般我们都是用 IDE 自动生成:这样的话别人一看到这样固定格式的注释(或者索性不要添加任何注释)就知道这部分相对于其他部分并不重要, 而一旦有的 getter/setter/isTrue 注释不是这样约定的,那就说明了实现上面不只是简单的 get/set/is,还加入了额外的逻辑处理。
对齐
Javadoc 文档注释也有对齐(不是前面 pre 例子那种),这里说的对齐主要指的是以源码视图看到的,最典型的场景就是在给方法添加文档注释的时候,我们经常看到两种风格:

第一眼看上去是不是风格 2 要顺眼得多?但最好还是使用风格 1,因为:
- 这和编辑器配置的字体有关,如果不是(适合的)等宽字体,那会非常的参差不齐
- 浪费空间,特别是当注释内容多了需要换行的时候会很别扭
- 最后生成的 apidocs 效果是一模一样的(无对齐)
(一些 IDE 默认格式化文档注释的时候也是使用风格 1 进行格式化的,强烈建议使用风格 1)
包注释
和前面几点打码风格相关的细节比起来,包注释是具有一定的实用性的。虽然大家可能用得很少,但看得应该比较多,就是这部分:

这里我们使用了两种方式来生成包文档:
- package.html:这是 JDK1.5 以前的方式,现在已经不推荐使用
- package-info.java:目前推荐方式,因为这样可以使用注解
在包上面使用注解?这个用法和在其他地方使用注解一样,只是被标注的元素变成了包,在运行时可以获取到包的注解,然后做你想做的事情吧!
中文
一开始我们提到了句号的问题(那的确是一个问题),最后我们来看看中文在写文档注释的时候也非常值得注意的一点(其实不只是 Javadoc 文档注释,该建议也适用于其他一些情况):在中文和英文、数字中间插入一个空格(本文就是这样排版的)。
比如说:
- 我觉得Java非常cool,特别是JDK8中的lambda,真希望9能带来更多实用特性
- 我觉得 Java 非常 cool,特别是 JDK8 中的 lambda,真希望 9 能带来更多实用特性
后者看上去就比前者更舒服一些,这样的排版方式适合纯文本编辑器,如果使用的是 Office 之类的工具就不需要手动空格了,因为它们默认已经处理的很好了。
总结
本文介绍了一些 Javadoc 文档注释相关的细节,从这冰山一角相信你对 Java 也有了另一番体验(Java 的进化、工业化)。
总结一下本文内容:
- 对于文档标记,大家可以尽量尝试使用:把自己的思想通过适合的方式表达给他人是一种好习惯
- 对于风格相关,大家也可以适当尝试(处女座/强迫症就算了):某大厂在某次改句号问题后出现过生产故障
不过,大家也千万不要太较真,毕竟对于一个好的程序来说,代码应该就是它的文档(之一)。
@转自 http://88250.b3log.org/when-the-little-things-count-javadoc